Bean的循环依赖问题
本文最后更新于:2024年9月8日 晚上
Bean的循环依赖问题
什么是循环依赖?
- 从字面上来理解就是A依赖B的同时B也依赖了A,就像下面这样。

1 | |
什么情况下循环依赖可以被处理?
- Spring解决循环依赖的前置条件。
- 出现循环依赖的Bean必须要是单例。
- 依赖注入的方式不能全是构造器注入的方式。
- 如果A中注入B的方式是通过构造器,B中注入A的方式也是通过构造器,这个时候循环依赖是无法被解决,如果你的项目中有两个这样相互依赖的Bean,在启动时就会报出以下错误:
1 | |
- 循环依赖的解决情况跟注入方式的关系:
| 依赖情况 | 依赖注入方式 | 循环依赖是否被解决 |
|---|---|---|
| AB相互依赖(循环依赖) | 均采用setter方法注入 | 是 |
| AB相互依赖(循环依赖) | 均采用构造器注入 | 否 |
| AB相互依赖(循环依赖) | A中注入B的方式为setter方法,B中注入A的方式为构造器 | 是 |
| AB相互依赖(循环依赖) | B中注入A的方式为setter方法,A中注入B的方式为构造器 | 否 |
- 不是只有在setter方法注入的情况下循环依赖才能被解决,即使存在构造器注入的场景下,循环依赖依然被可以被正常处理掉,但是要确保第一个初始化的Bean为setter方法注入。
Spring是如何解决的循环依赖?
- 关于循环依赖的解决方式应该要分两种情况来讨论。
- 简单的循环依赖。
- 结合了AOP的循环依赖。
简单的循环依赖
1 | |
- 首先Spring在创建Bean的时候默认是按照自然排序来进行创建的,所以第一步Spring会去创建A,与此同时,Spring在创建Bean的过程中分为三步。
- 实例化,对应方法:
AbstractAutowireCapableBeanFactory中的createBeanInstance方法。 - 属性注入,对应方法:
AbstractAutowireCapableBeanFactory的populateBean方法。 - 初始化,对应方法:
AbstractAutowireCapableBeanFactory的initializeBean
- 实例化,对应方法:

- 创建A的过程实际上就是调用
getBean方法,这个方法有两层含义。- 创建一个新的Bean
- 从缓存中获取到已经被创建的对象。
调用getSingleton(beanName)
- 首先调用
getSingleton(a)方法,这个方法又会调用getSingleton(beanName, true)
1 | |
getSingleton(beanName, true)这个方法实际上就是到缓存中尝试去获取Bean,整个缓存分为三级。singletonObjects,一级缓存,存储的是所有创建好了的单例BeanearlySingletonObjects,完成实例化,但是还未进行属性注入及初始化的对象。singletonFactories,提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象。
- 因为A是第一次被创建,所以不管哪个缓存中必然都是没有的,因此会进入
getSingleton的另外一个重载方法getSingleton(beanName, singletonFactory)
调用getSingleton(beanName, singletonFactory)
- 创建Bean
1 | |
- 上面的代码通过
createBean方法返回的Bean最终被放到了一级缓存。
调用addSingletonFactory方法
- 在完成Bean的实例化后,属性注入之前Spring将Bean包装成一个工厂添加进了三级缓存中。
1 | |
- 这里只是添加了一个工厂,通过这个工厂(
ObjectFactory)的getObject方法可以得到一个对象,而这个对象实际上就是通过getEarlyBeanReference这个方法创建的,当创建B的流程中会调用这个工厂的getObject方法。 - 当A完成了实例化并添加进了三级缓存后,就要开始为A进行属性注入了,在注入时发现A依赖了B,那么这个时候Spring又会去
getBean(b),然后反射调用setter方法完成属性注入。

- 因为B需要注入A,所以在创建B的时候,又会去调用
getBean(a),这个时候就又回到之前的流程了,但是不同的是,之前的getBean是为了创建Bean,而此时再调用getBean不是为了创建了,而是要从缓存中获取,因为之前A在实例化后已经将其放入了三级缓存singletonFactories中,所以此时getBean(a)的流程如下。

- 从这里我们可以看出,注入到B中的A是通过
getEarlyBeanReference方法提前暴露出去的一个对象,还不是一个完整的Bean
1 | |
- 该方法实际上就是调用了后置处理器的
getEarlyBeanReference,而真正实现了这个方法的后置处理器只有一个,就是通过@EnableAspectJAutoProxy注解导入的AnnotationAwareAspectJAutoProxyCreator,也就是说如果在不考虑AOP的情况下,上面的代码等价于
1 | |
- 这个工厂直接将实例化阶段创建的对象返回了,所以说在不考虑
AOP的情况下三级缓存没有起到作用。
- 注意:B中提前注入了一个没有经过初始化的A类型对象是否会有问题,这个时候我们需要将整个创建A这个Bean的流程走完,如下图:

- 从上图中我们可以看到,虽然在创建B时会提前给B注入了一个还未初始化的A对象,但是在创建A的流程中一直使用的是注入到B中的A对象的引用,之后会根据这个引用对A进行初始化,所以这是没有问题的。
结合了AOP的循环依赖
- 三级缓存实际上跟Spring中的
AOP相关,getEarlyBeanReference的代码如下:
1 | |
- 如果在开启
AOP的情况下,那么会调用AnnotationAwareAspectJAutoProxyCreator的getEarlyBeanReference方法,对应的源码如下:
1 | |
- 回到上面的例子,我们对A进行了
AOP代理的话,那么此时getEarlyBeanReference将返回一个代理后的对象,而不是实例化阶段创建的对象,这样就意味着B中注入的A将是一个代理对象而不是A的实例化阶段创建后的对象。

明明初始化的时候是A对象,那么Spring是在哪里将代理对象放入到容器中的呢?
- 在完成初始化后,Spring又调用了一次
getSingleton方法,这一次传入的参数又不一样了,false可以理解为禁用三级缓存,前面图中已经提到过了,在为B中注入A时已经将三级缓存中的工厂取出,并从工厂中获取到了一个对象放入到了二级缓存中,所以这里的这个getSingleton方法就是从二级缓存中获取到这个代理后的A对象,exposedObject == bean可以认为是必定成立的,除非你非要在初始化阶段的后置处理器中替换掉正常流程中的Bean,例如增加一个后置处理器。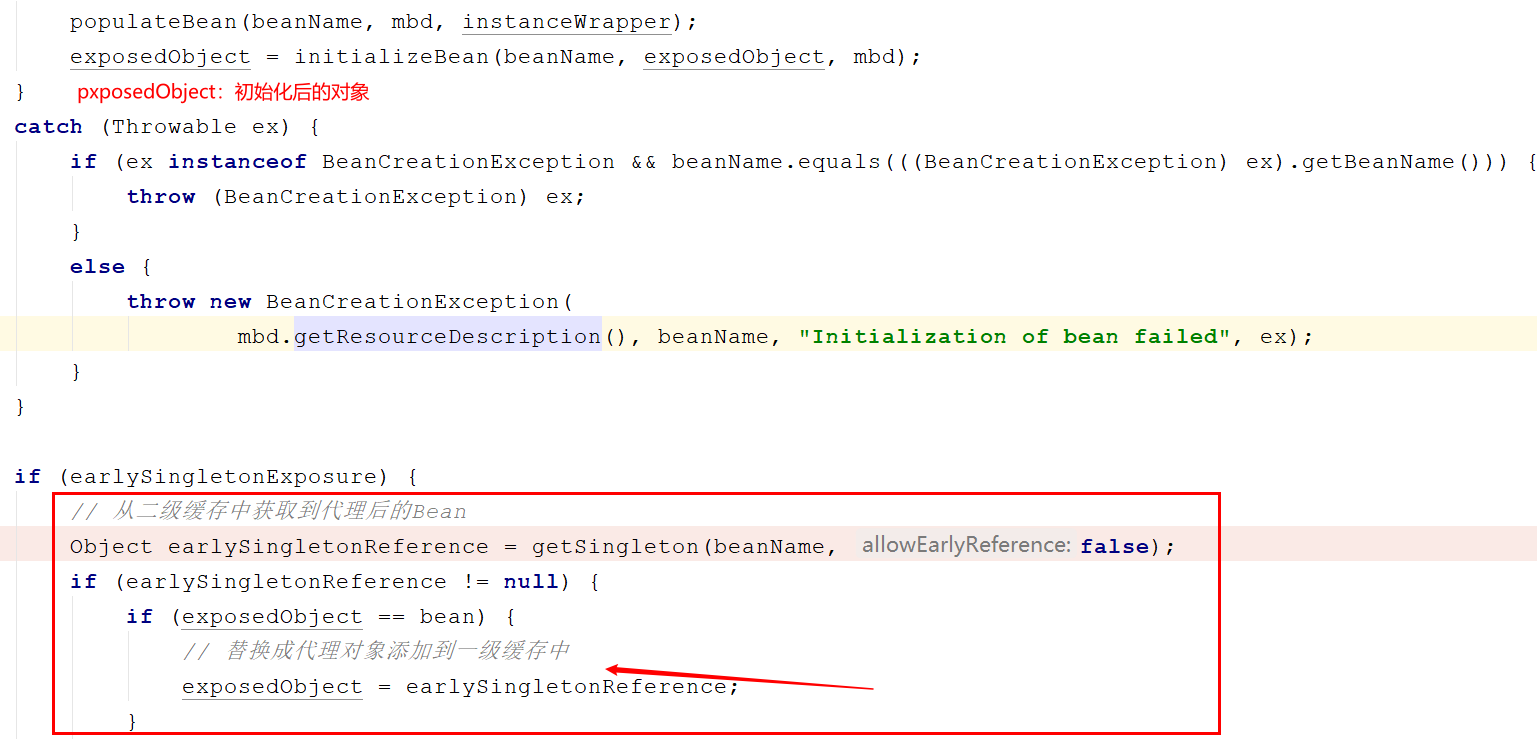
为什么需要三级缓存,直接通过二级缓存暴露一个引用不行吗?
这个工厂的目的在于延迟对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象。
我们思考一种简单的情况,就以单独创建A为例,假设AB之间现在没有依赖关系,但是A被代理了,这个时候当A完成实例化后还是会进入下面这段代码:
// A是单例的,mbd.isSingleton()条件满足。 // allowCircularReferences:这个变量代表是否允许循环依赖,默认是开启的,条件也满足。 // isSingletonCurrentlyInCreation:正在在创建A,也满足。 // 所以earlySingletonExposure=true boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName)); // 还是会进入到这段代码中。 if (earlySingletonExposure) { // 还是会通过三级缓存提前暴露一个工厂对象。 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); }可以得出,即使没有循环依赖,Spring 也会将其添加到三级缓存中,因为到目前为止Spring也不能确定这个Bean有没有跟别的Bean出现循环依赖。
假设在这里直接使用二级缓存的话,那么意味着所有的Bean在这一步都要完成AOP代理,这样做不仅没有必要,而且违背了Spring在结合AOP跟Bean的生命周期的设计!
Spring结合AOP跟Bean的生命周期本身就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理器的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理,如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。

三级缓存真的提高了效率了吗?
-
没有进行
AOP的Bean间的循环依赖。- 从上文分析可以看出,这种情况下三级缓存根本没用!所以不会存在什么提高了效率的说法。
-
进行了
AOP的Bean间的循环依赖。- 就以我们上的A,B为例,其中A被
AOP代理,我们先分析下使用了三级缓存的情况下,A,B的创建流程。
- 就以我们上的A,B为例,其中A被
- 假设不使用三级缓存,直接在二级缓存中。
- 上面两个流程的唯一区别在于为A对象创建代理的时机不同,在使用了三级缓存的情况下为A创建代理的时机是在B中需要注入A的时候,而不使用三级缓存的话在A实例化后就需要马上为A创建代理然后放入到二级缓存中去,对于整个A,B的创建过程而言,消耗的时间是一样的。
- 综上,不管是哪种情况,三级缓存提高了效率这种说法都是错误的!
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!